
I have been working in Artificial Intelligence (AI) since the start of my career in 2002. Over the past years I have seen perceptions of AI change quickly from a somewhat obscure field at the fringes of Computer Science, to making headlines. For example, about what it will do with our social relations, whether technology could harm us, and how it will affect our human agency.
Amidst all this buzz surrounding AI and the related field of Data Science, I thought it useful to write down my own views and position. I do this from three perspectives that represent the “why” (application), “how” (technique) and “what” (concept) of my research: Responsible Data Sharing (which can be generalised to supportive technology), Interactive Machine Reasoning, and Responsible Agency. Addressing the responsibility we have as scientists and engineers towards people and society is also a central theme in my teaching. You can read more about this on a separate page on Teaching Responsible Computer Science & AI.
Responsible Data Sharing
Data Science is often equated with Data Analytics: given large volumes of data, how can we extract useful information. I focus on the other side of the same coin: the role of digital technology in data sharing, and in particular how to do this in a responsible way that respects norms and values of people.
Data Sharing and Intimate Technologies
In a talk in 2016 I characterised Responsible Data Sharing through three “Rs”: Respect (for human norms and values), Reliability (in complying with them), and Resilience (in dealing with non-compliance).
This is of central concern for intimate technologies which commonly collect highly personal data and information. This data is often shared with the user and other people in the user’s social environment through the application. Moreover, data sharing occurs between user and various institutions, desired or not as we have seen in the Cambridge Analytica scandal. And sometimes data is obtained without consent by malicious parties. My research focus so far has been on the application layer. The different but related data sharing concerns at the application layer and the platform layer can be compared with the distinction between social privacy and surveillance privacy (Guerses & Diaz, 2013).
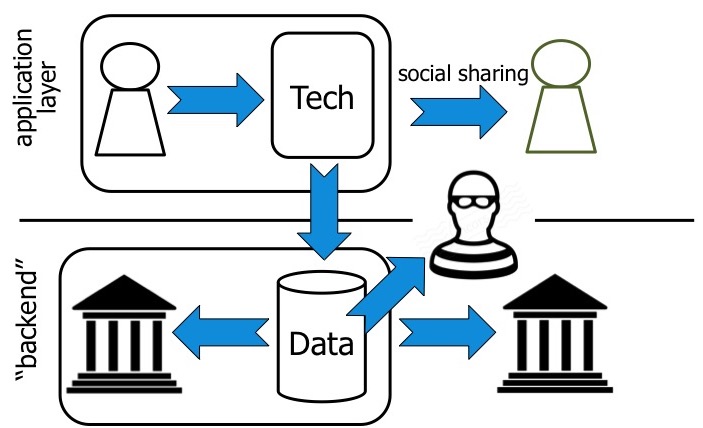
Flexible Intimate Technologies
The problem with existing intimate technologies is that they are typically inflexible: they take an all-or-nothing approach to social data sharing. For example, the starting point of GPS tracking technologies is typically that continuous access to a person’s location is provided. However, sharing personal information with other people makes us vulnerable.* It is my view that intimate technologies should take this vulnerability into account at run-time when deciding which data to share when with whom.
This would create a flexible “middle ground” between sharing all of the data all of the time and not using the technology at all. And this flexibility in accommodating norms and values of people applies not only to data sharing technologies, but in general concerns supportive technologies that recommend or perform actions on behalf of the user. By making intimate technologies more flexible, people can enjoy the technologies’ benefits while mitigating some of its risks.
*) Sharing data with institutions and service providers also brings with it specific vulnerabilities, however due to their different nature these require a separate analysis, see e.g., Madden et al. (2017).
More resources
Do you want to know more about the Responsible Data Sharing perspective on Intimate Technologies? Then check out these resources!
- Masterclass (2017) — Responsible Data Sharing: A Vision of Human-Technology Partnership
- PhD thesis of Dr. Alex Kayal (2017) on flexible mobile location sharing for families based on norms and values of users; some related papers:
- Social sensing on demand (demo, paper and video, 2014): how to involve people in collecting and sharing data about our environment in a flexible demand-driven way
- For more information, see my media articles and slides!
Interactive Machine Reasoning
To realise flexible intimate technologies that take into account human vulnerabilities at run-time, I use Artificial Intelligence (AI) techniques. AI is a broad field, within which one has traditionally distinguished two main subareas:
- data-driven AI: machine learning algorithms to detect (implicit) patterns in data in a bottom-up way
- knowledge-based AI: explicit representation of knowledge, for example in a rule-based form, accompanied with reasoning mechanisms to derive new information
I argue that a third component is missing, namely interaction. My research expertise is in connecting reasoning and interaction, sometimes used in combination with data-driven techniques. I call this interactive machine reasoning; see also a video I created providing an overview of the Vidi project CoreSAEP, with more background on these ideas. We currently investigate this through several of the projects within the 10-year Hybrid Intelligence gravitation programme.
Data-driven and knowledge-based AI
In knowledge-based approaches, representation and reasoning are explicit. An advantage of this is that they are more amenable to explanation of how a conclusion was reached. This is important for understanding and possibly contesting what the machine does. With machine learning this is more difficult due to a complex learned relation between input and output. However the advantage of machine learning is that we do not have to model potentially vast amounts of knowledge explicitly, which can be infeasible in practice. The following video provides a short introduction to the area of Knowledge Representation & Reasoning, created for a 3rd year bachelor course in Computer Science.
Introduction to Knowledge Representation & Reasoning (KRR Course) from University of Twente on Vimeo.
Considering the complementarity of strengths and weaknesses in these approaches, I think it is crucial that we advance on both fronts and ultimately bring them together. As advocated by the European AI network CLAIRE, excellence in AI requires all of AI.
Learning and reasoning are not enough
However, learning from (behavioural) data is not enough, especially for intimate technologies that support people in their daily lives:
- Availability of data: The availability of data about the behaviour of the supported person can be limited. For example when s/he just starts out using the technology, or because there are restrictions on which data can be collected. Part of this may be remedied by aggregating data from multiple users, but for truly personalised support we need to focus on the specifics of the user (small data).
- Data is historical: Data is about the past. If we want to support people in changing their habits we also need to model their desired future behaviour.
- Data misses the “why”: Observations about daily behaviour do not tell us why a person does what they do. In order to provide appropriate support the technology needs to know for example which values or social agreements underly the user’s behaviour in that context.
Knowledge-based approaches can complement machine learning. This is because they do facilitate representation and reasoning about desired behaviour, social agreements, and their underlying values. However, this knowledge is not available at design time. It must be constructed with users at run-time.
Reasoning and Interaction

Thus it is my view that an important component is missing from AI as learning + reasoning: interaction. And interaction is more than explanation or control. If we want to create technology that truly supports and collaborates with humans, we need to fundamentally design for interdependence.
We need models and reasoning techniques that allow back and forth knowledge construction and interpretation between human and machine. I refer to this as Interactive Machine Reasoning* (in analogy with Interactive Machine Learning). This requires different kinds of models and reasoning techniques compared to offline models that are constructed and used by experts:
- Expressivity
- User requirements should inform models: models should be expressive enough to represent what is important to a user and their social environment;
- Computational characteristics should inform models: models should be sufficiently simple that they can be reasoned about at run-time, as well as understood by users.
- Interactive knowledge construction and interpretation
- Norm dynamics: social agreements and user goals arise at run-time;
- Context dynamics: appropriate interpretations and required background knowledge may change depending on context
Fleshing out this multidisciplinary area is a main focus of our research for the coming years.
*) Searching for this term in Google gives me only 1 (!) result, I am amazed that this is still possible!
Responsible Agency
Since the start of my career I have been intrigued by the possibility of creating digital technologies that act. And in particular digital technologies (“agents”) that act in concert with and in support of people. Initially I worked on techniques for improving human-agent team performance.
However my focus started to shift around 2011 when the potential of Big Data began to influence scientific and public discourse. I realised that especially for intimate technologies it is just as important how people experience them, in particular when it comes to people’s agency (Technology for Humanity). And how acting with and through these technologies shapes who we are as people. Addressing these considerations is what “Responsible Agency” is about.
{kind=link}
Human Agency
Human agency is one of 7 requirements listed in the European Ethics Guidelines for Trustworthy AI. My work on this started with the observation that existing supportive technology is rigid: it hardwires norms into the technology, and as a consequence violates unsupported norms and values of people. In other words, it limits our agency to shape our lives in alignment with what we find important. Our research on software that takes into account human norms and values addresses this.
We conceptualise such flexible supportive technology as so-called Socially Adaptive Electronic Partners (SAEPs). The crucial characteristic of a SAEP is that it “belongs to” an individual person. A SAEP supports someone while taking into account what is important to them, and how they want to relate to other people. Many intimate technologies are inherently personal, which makes it natural to conceptualise them as SAEPs.
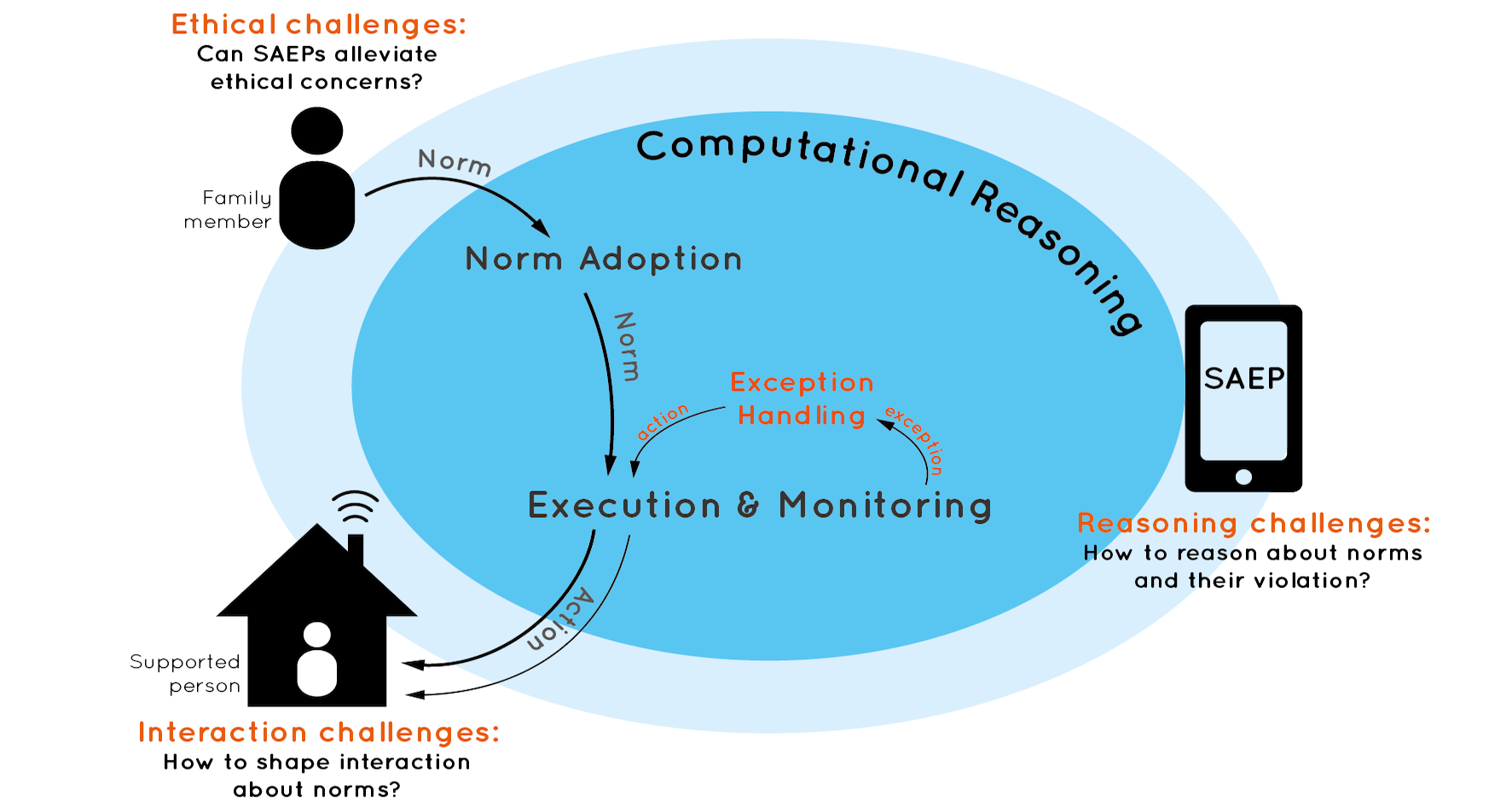
A central design principle of SAEPs is that we regard the supported person as the primary moral agent. Our focus is not to endow agents with (general) ethical reasoning capabilities as is typically the aim of machine ethics. What is the “right” decision about how to support a person is highly context-dependent and personal. The SAEP needs to figure this out by “getting to know” in an interactive way what is important to the supported person. And while doing so always leaving space for what it may not understand. In this way it allows people to develop and take their responsibility, which is how one can connect the notions of responsibility and human agency (Friedman, 1992).
Human-Machine Coaction

Human agency is thus central to our vision of supportive technology. However, this does not mean we can see our actions as independent from this technology. As philosopher prof. Peter-Paul Verbeek says, technology mediates our actions. For example, technologies can present us with options that we did not have before, and encourage or inhibit certain actions. This means that technology is not only a tool that we use to give shape to our (moral) agency, but vice versa it also plays a role in shaping us as moral subjects. Human agency or freedom then is not the absence of influences and constraints, but our ability to relate to them.
Correspondingly, developing supportive agent technology in a responsible way requires consideration of how human and machine jointly produce actions in the world as a co-entity. That is, we need to think about human-machine coaction. Different kinds of human-machine coaction may be distinguished (and combined) in supportive technology:
- Support action: the machine provides behaviour support to the user by, for example, recommending which action to take or reminding the user about their values when they are about to take an undesired action. Here the machine co-shapes action through its support, but does not take over actions on behalf of the user;
- Delegation: the user delegates the performance of (parts of) actions and tasks to the machine, for example in the case of service or care robots, automatic location sharing technology, or self-driving cars. A variant of this may be “covert” action, in which the technology takes actions such as share data unbeknownst to or undesired by the user;
- Conjoint action: in this case user and machine act simultaneously and “as one”, for example in the case of the autopilot function in cars where the driver is still holding the steering wheel, or high-tech clothing in which the clothing can decide to change colour or shape depending on the state of the user and other contextual factors.
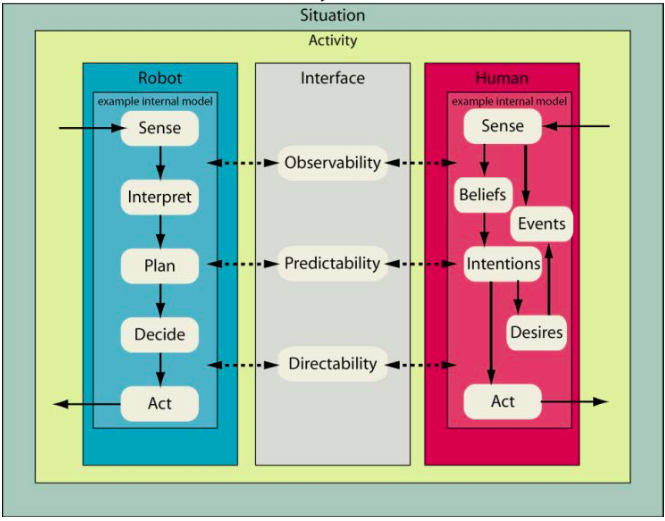
To systematise development of resilient human-machine systems we have developed the Coactive Design method. It focuses on human-robot teamwork, which mostly concerns delegation. It is based on the identification of three types of interdependencies: Observability, Predictability and Directability (OPD).
What inspires me about this method is that it is not only about how humans can control the machine, or how the machine can explain itself to the human. Rather it considers the human-machine co-entity as a whole. Designing for “back-and-forth” interdependencies allows the human-machine team to handle unexpected situations and recover from failures. In this way it is also about what we need to dare and let go of control (a little). It is about “dancing” in our interactions with technology, making space for wonder in our intimate technological experiences.